Table of contents
- Introduction
- Functional Description
- Requirements
- Queries
- Design Considerations and Decisions
- Time Analysis
- Potential Areas for Improvement and/or Expansion
- Combiner Usage Analysis
- Additional Optimizations
- Conclusions
Introduction
This project defines a Map Reduce cluster using Hazelcast. The project compiles into two executables (a) client script to interact with the cluster (b) a server script to be run in each node of the cluster. Finally, communication is done through sockets. In addition to the actual queries, we did data analysis on how the number of nodes impacted the performance, as well as the use of Combiners, and KeyPredicates among other things. The task is to process parking ticket data from New York City, USA, and Chicago, USA. The data will be extracted from government portals in CSV format.
Functional Description
The application should process parking ticket data from New York City and Chicago, but the implementation should not be tied specifically to this use case. The statistics will be dynamically computed from the infraction file during execution. It should work for any city's parking data, as long as the data follows the format described below.
Parking ticket data for New York (ticketsNYC.csv):
- Source: Open Parking and Camera Violations
- Download:
/afs/it.itba.edu.ar/pub/pod/ticketsNYC.csv - Number of records: 15,000,000
- Fields:
Plate: License plate (String)Issue Date: Date of ticket (Format YYYY-MM-DD)InfractionCode: Infraction code (Integer)Fine Amount: Fine amount (Number)County Name: Neighborhood (String)Issuing Agency: Agency that issued the ticket (String)
Example data:
Plate;Issue Date;InfractionCode;Fine Amount;County Name;Issuing Agency
GXH1273;2022-08-25;36;50.0;Kings;DEPARTMENT OF TRANSPORTATION
F35GMJ;2017-07-30;53;115.0;New York City;TRAFFIC
HAN3178;2019-10-15;37;35.0;Queens;TRAFFICNew York infraction data (infractionsNYC.csv):
- Download:
/afs/it.itba.edu.ar/pub/pod/infractionsNYC.csv - Number of records: 97
- Fields:
Code: Infraction code (Integer)Definition: Infraction description (String)
Example data:
CODE;DEFINITION
87;FRAUDULENT USE PARKING PERMIT
67;PEDESTRIAN RAMP
85;STORAGE-3HR COMMERCIALParking ticket data for Chicago (ticketsCHI.csv):
- Source: City of Chicago Parking and Camera Ticket Data
- Download:
/afs/it.itba.edu.ar/pub/pod/ticketsCHI.csv - Number of records: 5,000,000
- Fields:
issue_date: Ticket date and time (Format YYYY-MM-DD hh:mm:ss)license_plate_number: License plate (UUID)violation_code: Infraction code (String)unit_description: Issuing agency (String)fine_level1_amount: Fine amount (Integer)community_area_name: Neighborhood (String)
Example data:
issue_date;license_plate_number;violation_code;unit_description;fine_level1_amount;community_area_name
2005-03-10 16:30:00;25515fcf196d56759b5ebdf9242553b7123f5233184cfb38c2a3f45cc33fe5c8;0964080A;CPD;50;LOOPChicago infraction data (infractionsCHI.csv):
- Download:
/afs/it.itba.edu.ar/pub/pod/infractionsCHI.csv - Number of records: 128
- Fields:
violation_code: Infraction code (String)violation_description: Infraction description (String)
Example data:
violation_code;violation_description
0968040J;MOTOR RUNNING IN WRIGLEY BUS PERMIT ZONE
0964160C;NO DISPLAY OF BACK-IN PERMITRequirements
The application must be able to solve a set of queries listed below. The results for each query will be written to a CSV output file, and performance measurements must be logged in a separate output file with timestamps.
For example:
$> sh queryX.sh -Daddresses='xx.xx.xx.xx:XXXX;yy.yy.yy.yy:YYYY' -Dcity=ABC -DinPath=XX -DoutPath=YY [params]Where:
- `queryX.sh` is the script for the specific query.
- `-Daddresses` refers to the IP addresses of the nodes with ports (one or more, separated by semicolons).
- `-Dcity` indicates which city's dataset to process, either NYC or CHI.
- `-DinPath` indicates the input file path for tickets and infractions.
- `-DoutPath` indicates the output file path for the results and timestamps.
Queries
Query 1: Total tickets per infraction
Each line in the output should contain the infraction and the total number of tickets with that infraction, ordered by ticket count in descending order and alphabetically by infraction as a tiebreaker.
- Example invocation: `sh query1.sh -Daddresses='10.6.0.1:5701' -Dcity=NYC -DinPath=. -DoutPath=.`
Example output for NYC:
Infraction;Tickets
PHTO SCHOOL ZN SPEED VIOLATION;25698186
NO PARKING-STREET CLEANING;11521009Query 2: Top 3 most common infractions per neighborhood
Each line should contain the neighborhood name, the top 3 infractions, or a “-” if fewer than three distinct infractions exist.
- Example invocation: `sh query2.sh -Daddresses='10.6.0.1:5701' -Dcity=NYC -DinPath=. -DoutPath=.`
Example output for NYC:
County;InfractionTop1;InfractionTop2;InfractionTop3
Bronx;PHTO SCHOOL ZN SPEED VIOLATION;NO PARKING-STREET CLEANING;FAIL TO DSPLY MUNI METER RECPTQuery 3: Top N agencies by percentage of revenue
Each line should contain the issuing agency and its percentage of total revenue, calculated from the sum of all fines.
- Example invocation: `sh query3.sh -Daddresses='10.6.0.1:5701' -Dcity=NYC -DinPath=. -DoutPath=. -Dn=4`
Example output for NYC:
Issuing Agency;Percentage
TRAFFIC;69.19%Query 4: License plate with most tickets per neighborhood in a date range
Each line should contain the neighborhood, the license plate with the most tickets, and the number of tickets within the given date range `[from, to]`.
- Example invocation: `sh query4.sh -Daddresses='10.6.0.1:5701' -Dcity=NYC -DinPath=. -DoutPath=. -Dfrom='01/01/2017' -Dto='31/12/2017'`
Example output for NYC:
County;Plate;Tickets
Bronx;94903JA;573Query 5: Infraction pairs with the same fine average in groups of hundreds
Each line should contain pairs of infractions whose average fine falls within the same group of hundreds (e.g., $200-$299). Do not list pairs where the average fine is below $100.
- Example invocation: `sh query5.sh -Daddresses='10.6.0.1:5701' -Dcity=NYC -DinPath=. -DoutPath=.`
Example output for NYC:
Group;Infraction A;Infraction B
500;BLUE ZONE;FAILURE TO DISPLAY BUS PERMITDesign Considerations and Decisions
Structure
The project structure uses Maven. This involves the separation into:
- API
- Server
- Client
Where the classes shared by both types of processes (server and client) will be in the API, and can be imported by the Server and Client. These classes include both the objects used for client-server communication and other common properties like the Hazelcast namespace, group name, password, etc.
The server will be the process that configures the Hazelcast instance, and upon execution, it will add a node to the cluster (or create it if it is the first node).
Finally, the Client will contain 5 processes (one for each query), where upon execution, it will handle accessing the Hazelcast cluster, uploading data, configuring, executing, and waiting for the Map-Reduce task to complete.
Class Hierarchy in Client
Within the client directory, the queries were organized so that there is an abstract class QueryClient.java that concentrates the logic for argument validation, uploading data, deleting data, etc. Additionally, it has abstract methods to be implemented by the specific query.
Moreover, there is an interface Result.java that must be implemented to form each line of the .csv output file. The process of writing the file is part of the QueryClient.java class.
.
├── api
├── server
└── client
├── src
│ └── main
│ └── java
│ └── ar.edu.itba.pod.tpe2.client
│ ├── QueryClient.java
│ ├── Result.java
│ ├── queryN
│ ├── queryName.java
│ └── queryNameResult.java
│ └── ...Considerations in Query Implementation
Use of MultiMap
When loading data into the cluster, both Map and MultiMap were used. For the same namespace, the Map stores the pairs [Infraction Code; Infraction Description]. However, to store ticket data, a MultiMap is used where the keys are license plates for each ticket, and a collection of infractions is obtained as the value, since the same license plate can have multiple tickets.
As alternatives, it was considered to only use maps and resolve key conflicts due to license plates in two possible ways:
- Use a collection (list) of infractions as the map value.
- Modify the license plates by adding an index, so that they become unique keys.
However, these were discarded in favor of using Hazelcast's MultiMap implementation.
Query Order
To ensure the required order of the queries, post-processing was done on the result obtained from the Map-Reduce. The implementations of Result.java implement the Comparable interface, allowing them to be inserted into a TreeSet collection, which will be written in order to the output file.
In the specific case of query number 5, alphabetical ordering of infraction types by columns, rather than tuples, was initially considered, as later clarified by the course.
Class Serialization in API
For serialization, the data classes implement DataSerializable. As an alternative, it was initially considered to format the class into a String type, where all the fields of the object would be included. When deserializing, the string would be taken, and an instance would be created based on the received string by copying the fields. This alternative was discarded in favor of an object-oriented implementation by using the DataSerializable interface for simplicity.
Use of KeyPredicate
When implementing query number 4, the idea arose to use KeyPredicate to discard entries where the date was not within the range.
However, since the data model in Hazelcast was approached with the license plate as the key, this potential optimization lost relevance.
Time Analysis
Node Characteristics and Methodology
For testing, we had 3 nodes with the following characteristics:
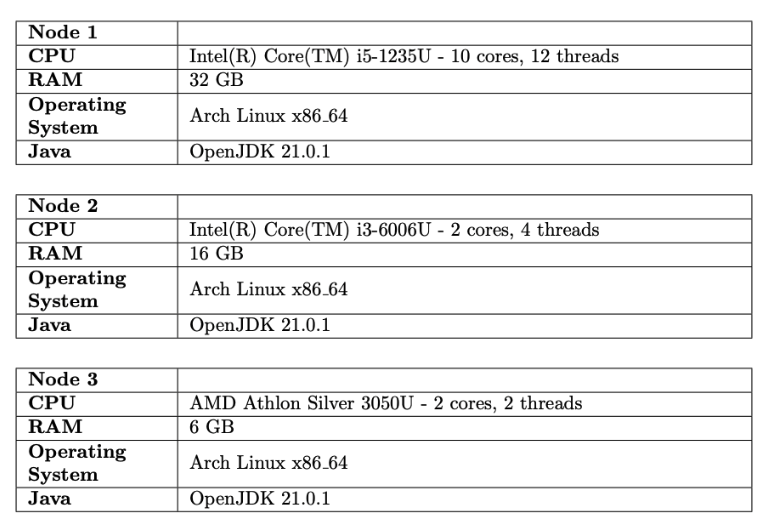
Additionally, a 100 Mbps switch was used for device connectivity. Below the respective plots of the speeds are presented:
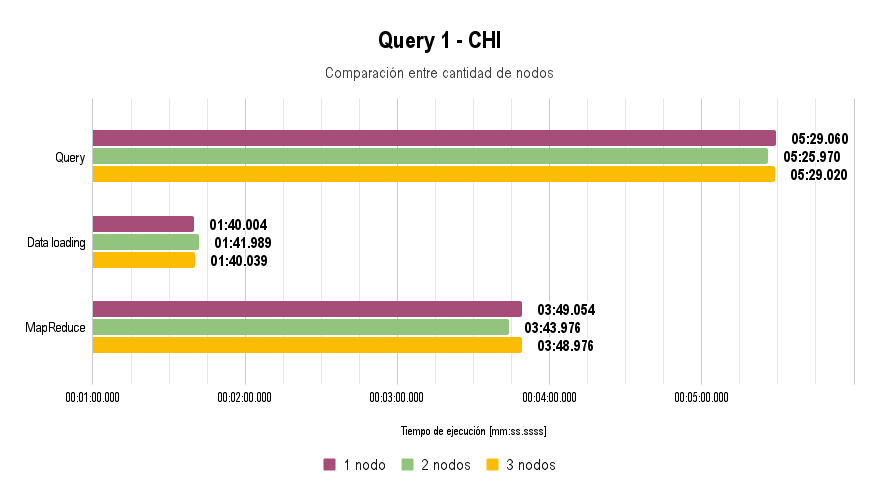
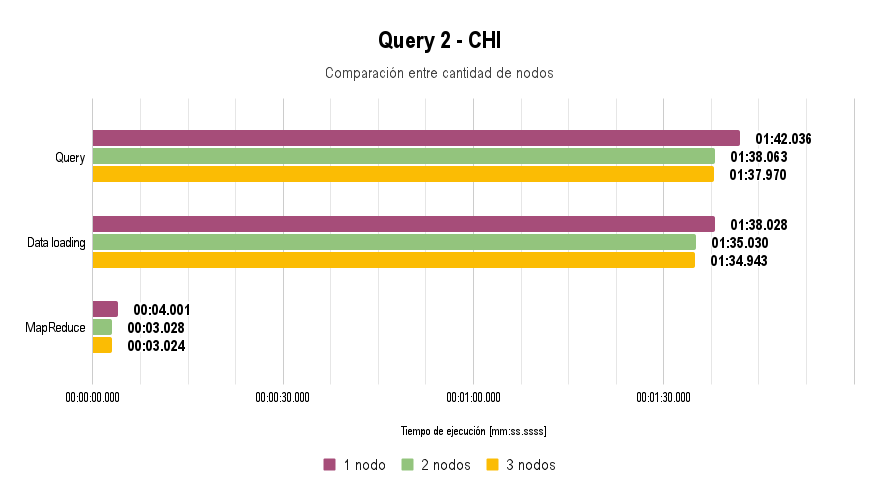
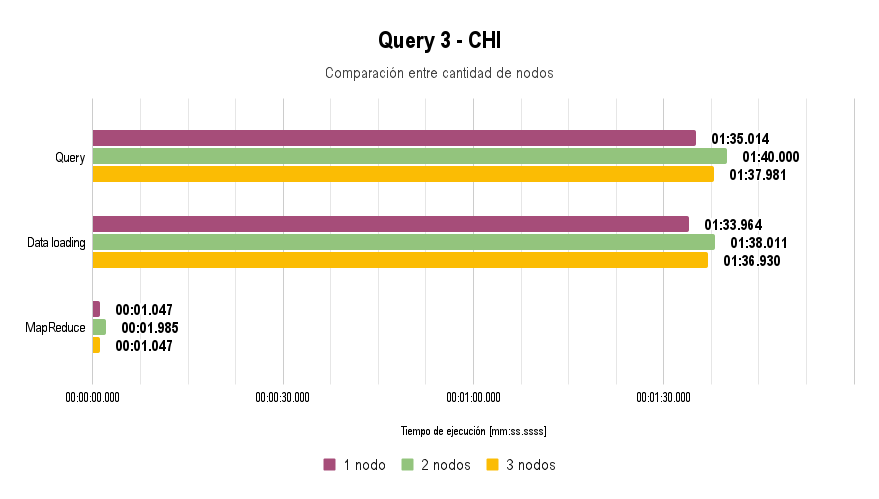
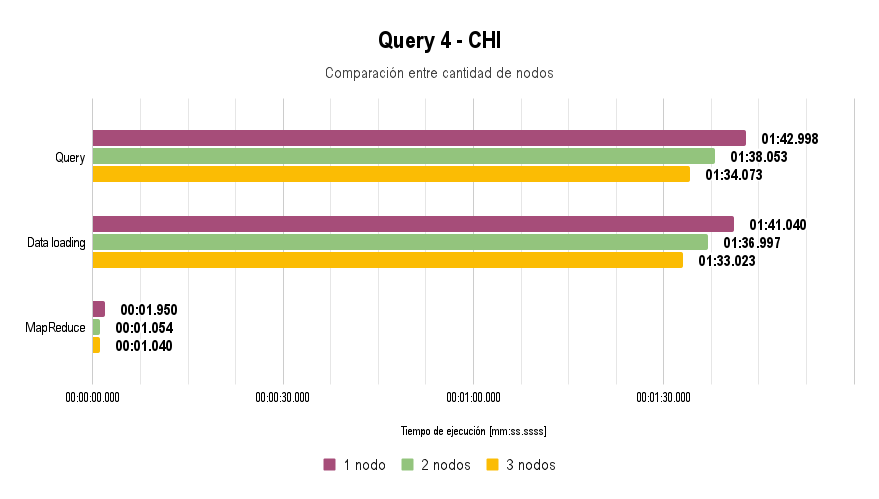
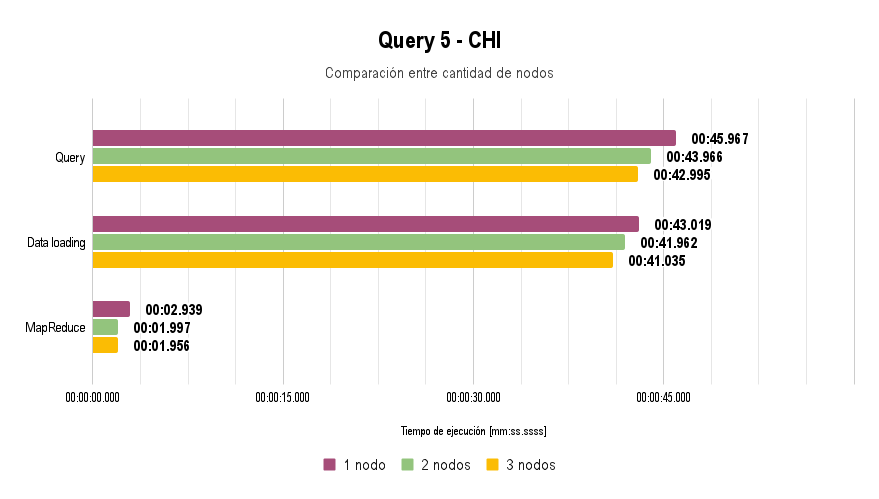
For the execution of all queries, a reduced dataset was used due to the limitation posed by the switch: data loading takes more than 45 minutes at a speed of 100 Mbps.
It is worth noting that for Query 3, the extra argument -Dn=5 was used, and for Query 4, the arguments -Dfrom="01/01/2004" and -Dto="31/12/2005" were used.
In all the graphs presented above, lower execution time is better.
Potential Areas for Improvement and/or Expansion
Use of KeyPredicate
As previously mentioned, there was an intention to implement a KeyPredicate optimization for query number 4, discarding entries whose date was not within the specified range.
A clear area for improvement is to modify how data is loaded into the MultiMap, where the key could be an object (as simple as a tuple) that includes the date, so that the KeyPredicate can be correctly implemented, filtering based on whether the date in the key falls within a certain range.
Further Optimization of Data Loading
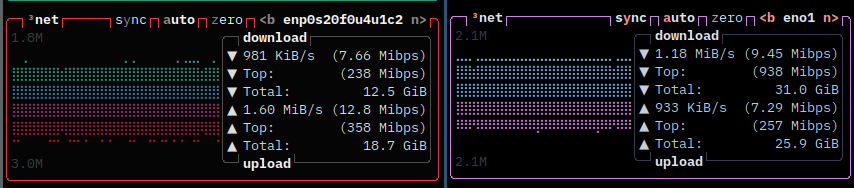
Network Devices
A simple optimization in our particular case would be to use a 1 Gbps or, ideally, a 10 Gbps switch. During our tests, we analyzed the traffic on the LAN interfaces of each node and noticed that the network was a bottleneck.
Uploading Only Necessary Data
An optimization made was that for queries that do not require certain data, they are loaded as empty (empty string, number 0, etc.). This could be further improved by modifying the maps loaded into the Map-Reduce cluster so that the loaded objects contain only the fields necessary.
Combiner Usage Analysis
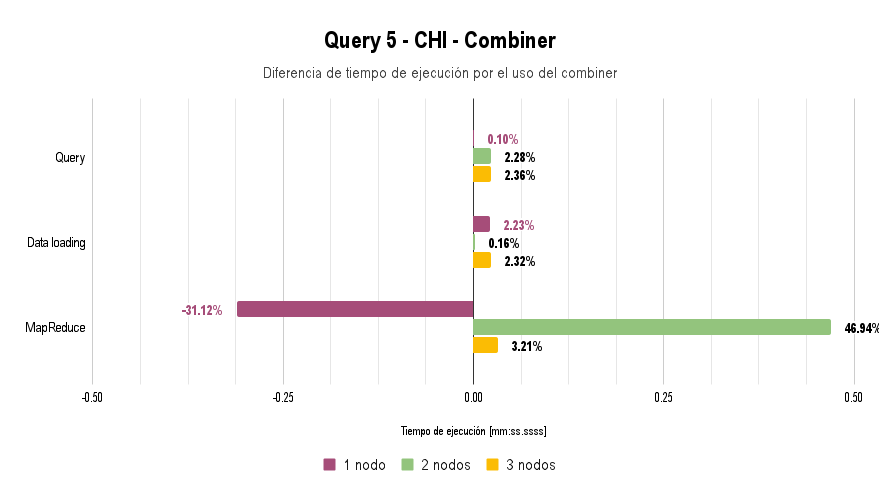
When implementing the Combiner for Query 5, we noticed that performance decreased in all cases except when performing MapReduce on a single node.
This optimization is implemented in a branch that is not the main one. To test this optimization, the implement-combiner branch must be used.
Additional Optimizations
An additional optimization we made was to reduce the amount of network traffic when uploading files.
Initially, we uploaded all attributes for all queries, but after conducting performance analyses, we concluded that the bottleneck was in uploading data to the cluster, particularly the network bandwidth.
As a result, when uploading files, we only populated the attributes necessary for each specific query, leaving the rest as 0 or empty Strings. This significantly reduced the bytes transferred over the network when uploading serialized objects to the cluster without losing the ability to use the same object serialization across different queries.
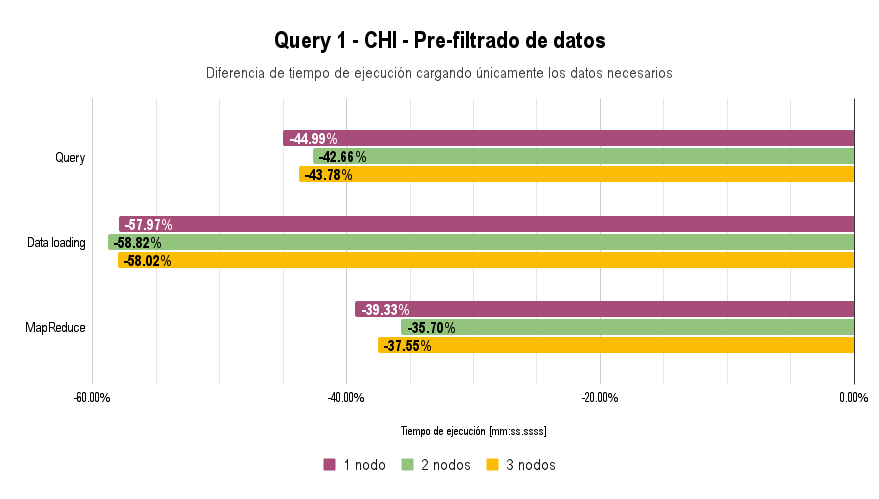
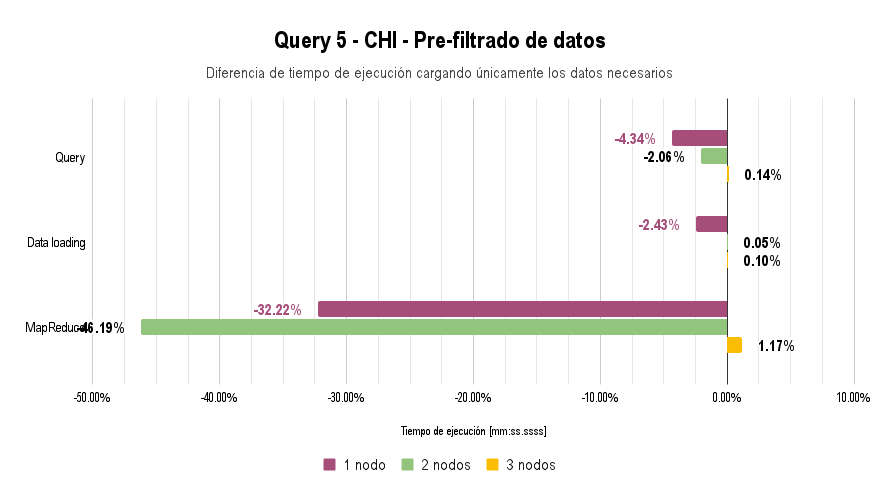
This optimization was implemented in the implement-aux-optimization branch of the repository.
Conclusions
In conclusion, we successfully implemented distributed data processing through Hazelcast and Java. We also analyzed different cluster variations and their impact on processing time. Additionally, we went beyond MapReduce by using a Combiner to compare performance in our specific application, demonstrating that various design decisions may be faster in theory but not necessarily in practice.